
Have you ever wondered why it’s so hard to get a straight answer to a simple question: "How much time will this feature actually take?"
In an ideal world, Jira tasks are like "Unicorns": one owner, one clear scope, and one estimate that never changes. But in reality, the moment the sprint starts, this illusion falls apart.

When we spoke at ACE Prague recently, we asked the audience a simple question: "Who here fully trusts the numbers in their Original Estimate field?" The silence in the room spoke volumes.
After 15 years of building Jira apps and observing hundreds of teams, we’ve realized: Jira’s native time-tracking is a "lonely monologue," while modern development is a "dialogue."
After 15 years of building Jira apps and observing hundreds of teams, we’ve realized: Jira’s native time-tracking is a "lonely monologue," while modern development is a "dialogue."

The "Sidebar of Pain": 3 Patterns That Break Your Data
Through our work on TeamTime for Jira, we’ve identified three technical gaps that inevitably force teams to abandon Jira for spreadsheets:
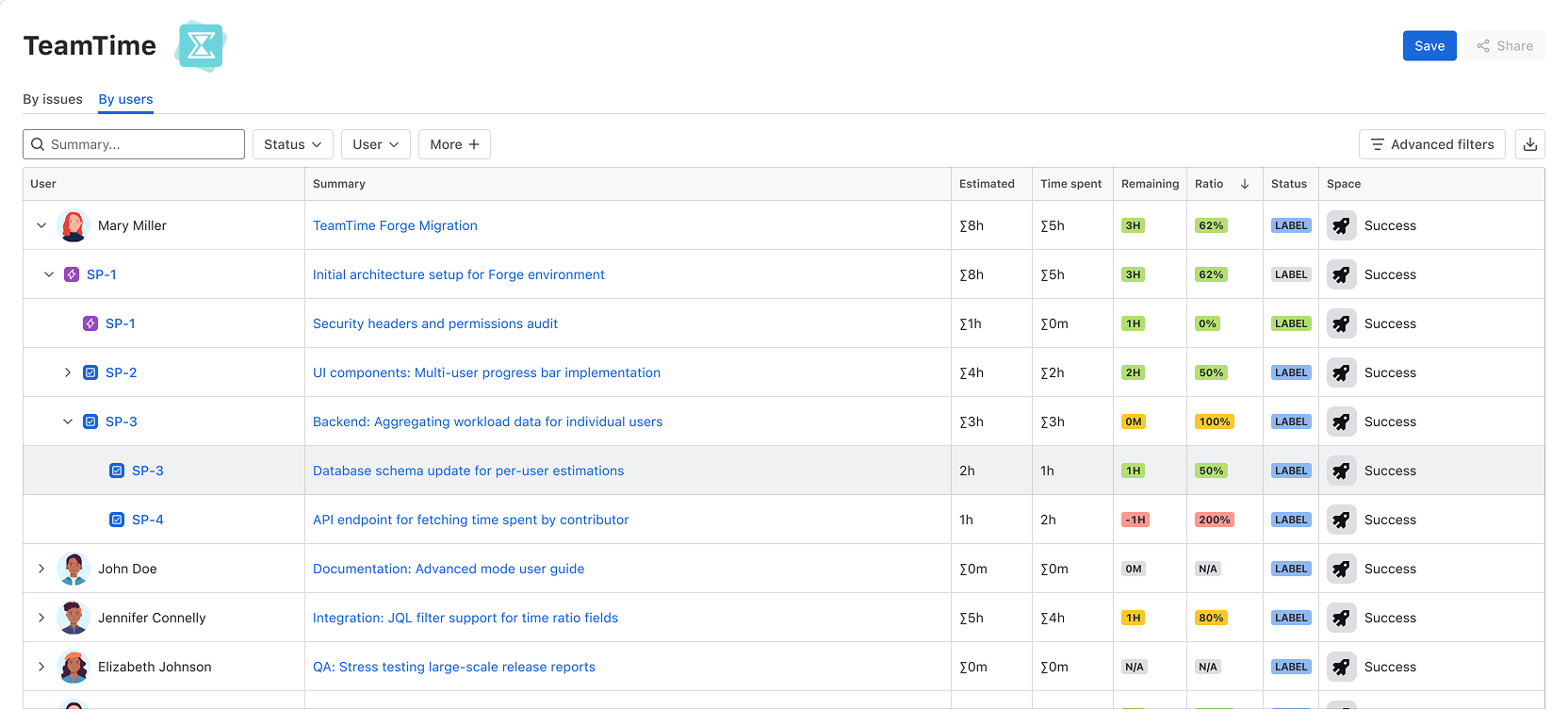
- The Non-Reactive Parent (The Roll-up Gap): You create ten sub-tasks and carefully refine their estimates. But the Parent issue (the Story or Task) remains stuck with its stale, original number. It doesn't "react" to changes below it. To see the actual total effort, you have to run manual JQL queries or build fragile automations. If your data isn't reactive, it isn't "live."
- The "Overwriting War" (The Collaboration Gap): Development is collaborative. A single ticket often requires input from a Developer, a QA, and a Designer. However, Jira’s estimate is a single field. Every time someone updates it, they overwrite the previous person's contribution. The history of "who estimated what" is lost, making it impossible to see the breakdown of effort by role.
- The Excel Escape (The Reporting Gap): When stakeholders ask for cross-project rollups or cost modeling based on roles, native fields fail. The moment you export data to a spreadsheet to "make sense of it," Jira officially stops being your "single source of truth."

The Shift: Moving from "Fields" to "Collaborative Models"
We realized that adding more custom fields isn't the answer. We needed to rethink how Jira processes effort data. This is why we are finalizing the Forge (Cloud-native) version of TeamTime Standard:
- Native Data Roll-ups: Estimates "flow" up automatically from Sub-tasks to Epics. You see the total effort directly in the Issue View.
- Estimates by User & Role: Instead of one overwritten number, we store effort per contributor. You can finally see the breakdown: who committed to what, and for how long.
- The "Bucket" Approach (Distributive Mode): For consulting and support, we’ve implemented a mode where worklogs consume a "pool" of hours dynamically.
Watch the Full Breakdown
We’ve captured our full session from ACE Prague, where we dive deep into these patterns and our vision for the future of Jira time-tracking.
Note: The new TeamTime Standard for Forge is in the final stages of release and will be available on the Marketplace soon.
Ready to fix your time-tracking?
If you are struggling with fragmented data or want to see how to implement these collaborative models in your Jira instance, we are always happy to help:
- Explore TeamTime to see how we solve these challenges.
- Book a quick demo with our experts for a personalized walkthrough.
- Reach out to our team directly at support@teamlead.one — we are ready to answer any questions!